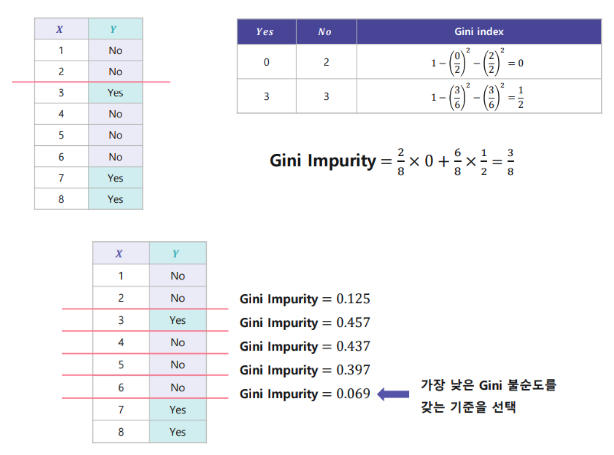
https://tomaszgolan.github.io/introduction_to_machine_learning/markdown/introduction_to_machine_learning_02_dt/introduction_to_machine_learning_02_dt/#cart Decision Trees - Introduction to Machine Learning Decision Trees Graphviz Installing graphviz !apt install -y graphviz !pip install graphviz A tree example from graphviz import Digraph styles = { 'top': {'shape': 'ellipse', 'style': 'filled..